
Sometimes, you may want to download entire website for offline view or archive. You must not want to download web pages one by one using browser’s saving function. You need a tool to download all files including all html pages, all images, etc., from the website. Site Downloader is such a website ripper that can download whole website. After downloading the full website, you can view the content by clicking the html files on your local disk, or if you installed web server such as xampp or wampp on your pc, you can copy the downloaded files to specific directory and view the website by typing the local address in the address bar of the browser(such as localhost/website). This is convenient if the website you download is not always online, or not always accessible for you.
Apart from saving website offline, Site Downloader can also act as a website copier. To copy website from one domain name to another, simply copying the downloaded files is not enough. The web page files contain references or links to original website which should be modified to point to the new website. Site Downloader integrates powerful content converter module and content rewriter module that can change the content of the original website at your will.

Contact us if you want to buy a license
How to use Site Downloader?
Site Downloader has a concise GUI. Input the domain name in the address bar and click “Go” button, Site Downloader will load the website in its main window. Then you can click the “Download” button to download what you want:
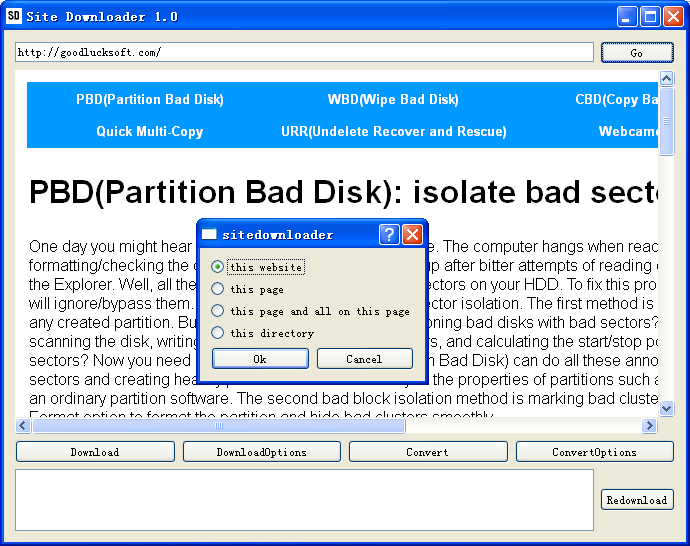
- this website
Download the complete website in the current main window. - this page
Just download the current page. - this page and all on this page
Download the current url and all urls contained on the current page. - this directory
Download all urls under the current directory. For example, the current url is: http://goodlucksoft.com/sitedownloader/index.php(you can see the current url in the address bar), then Site Downloader will download all the urls under http://goodlucksoft.com/sitedownloader/, such as http://goodlucksoft.com/sitedownloader/page1.html, http://goodlucksoft.com/sitedownloader/picture.png, etc., but won’t download http://goodlucksoft.com/otherdirectory/index.html, etc. Note that to download all urls under some directory of the website, you should start with a page under that directory and with enough links pointing to other pages under the same directory. If some urls under the directory cannot be crawled by Site Downloader due to lack of links pointing to them, they cannot be downloaded and saved to your local computer.
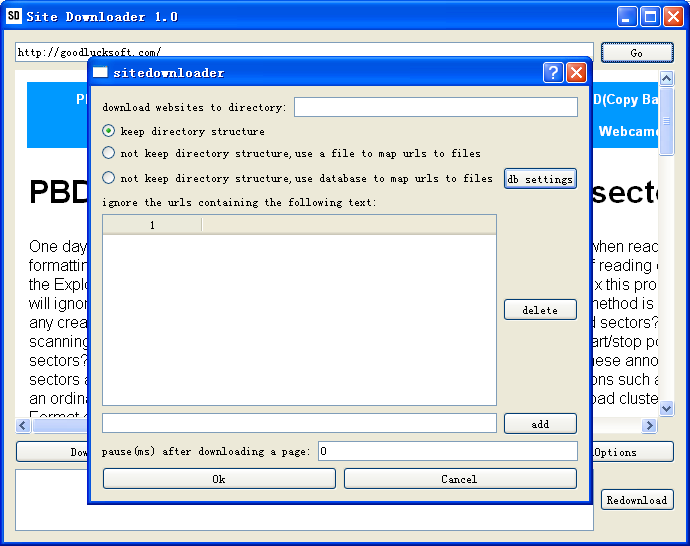
Click “DownloadOptions” button to find more options for download. Here you can specify where to save the downloaded websites(by default, the “downloaded” folder in the installation directory). You can specify how to save the offline website files. There are 3 methods to save downloaded web pages:
- keep directory structure
The offline website has the same directory structure as its online version. For example, if you download the entire website http://goodlucksoft.com to the folder downloaded/goodlucksoft.com on your PC, the webpage http://goodlucksoft.com/sitedownloader/index.html will be saved as downloaded/goodlucksoft.com/sitedownloader/index.html. This method is convenient for you to browse and edit the downloaded files as you can easily locate the offline version of a webpage. This method is especially appropriate for static html websites. - not keep directory structure, use a file to map urls to files
The method will save all webpages to one folder. The file names of offline webpages are randomly generated and a map file is used to map the url to the file name. This method is useful to duplicate a website. All you have to do is downloading the entire website and uploading(after possible converting and rewriting) the files in the folder to the root directory of the new website on the server. This method is especially useful if your new website is on a low-end shared host without database support. - not keep directory structure, use database to map urls to files
Same as the previous method, this method is not appropriate for you to edit the downloaded files manually because the downloaded files are named randomly and put in a single folder.
It is different from the previous method in that it uses database to map urls to files, which is more efficient if you clone a large website with many urls. Before using this method, you should do the database settings such as configuring host,database name, user name, and password. It would not be a problem for you if you’ve set up a wordpress website or other types of website that uses database. When it is time for you to copy the downloaded content to the new website, you should upload the files as well as export/import the database that contains the map information.
You can choose not to download certain webpages by specify the patterns in the urls. You can also specify a pause interval between downloading webpages in order not to be banned.
During the download process, the downloaded urls will be displayed in the box below. You can re-download a url in the box later.
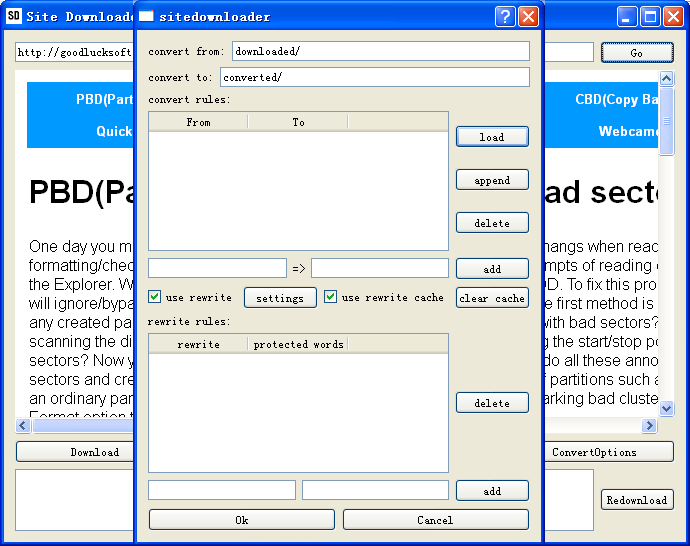
After all the webpages are downloaded from the website, it comes to the excellent part of Site Downloader: convert. Unless the website is very simple, it is necessary to convert the downloaded pages to be viewed and navigated correctly offline. Xampp or wampp are common used tools to browse downloaded website on you PC. If you use xampp, you can copy the website folder to the htdoc directory under xampp’s installation directory, then open a browser window, and type localhost/websitefolder to browse the website off-line. You will notice the links on the off-line page may still point to the on-line webpages. Clicking those links will bring you to the online version of the webpages instead of the offline version. This is why you should use the converting function of Site Downloader. At least you should convert all hrefs containing the original domain to localhost/websitefolder to make the navigation work correctly. The converting function of Site Downloader can do more than that. Click the “Convert” button, you can find all options related to converting and rewriting. You can specify the source directory of converting(usually the download directory of the website) and the destination directory where the converted files are stored. You can add as many converting rules as you want. A convert rule is a combination of a regular expression specifying what to change, and a string that is replaced with. For example, the converting rule goodlucksoft.com=>ocalhost/goodlucksoft.com will substitute “localhost/goodlucksoft.com” for all occurrences of “goodlucksoft.com” in the downloaded files. The converting rule olddomainname.com=>newdomainname.com will replace all occurrences of “olddomainname.com” with “newdomainname.com”. Note that it is not simple string substitution but regular expression replacement.
Compared to converting which is relatively rigid, rewriting is more flexible. Rewriting is rewording or rephrasing the original content to generate something different but similar. To use the rewriting function, you should check on the “use rewrite” option and configure a rewriter tool first. Site Downloader supports TBS(The Best Spinner) at present. More article rewriter tools such as SpinnerChief will be supported in the future. The settings for each content spinner are different. For TBS, you need to fill the email and password. You can tick the “use rewrite cache” to cache the rewriting results,which is sometimes expensive considering the network communication with the spinner’s server and its limitation on the request number per day. After configuring a paraphrasing tool, you need to tell it what to rephrase by adding one or more rewrite rules. A rewrite rule consists of a regexp specifying which part of the webpage is to be reworded(i.e.,<div id=”id1″>([^<>]*)</div> means the text between <div id=”id1″> and </div> will be spun), and one or more protect word regexps specifying the words on the page that are not to be changed(for example, keyword1|keyword2 means keyword1 and keyword2 in the to-be-spun text will not be rewritten).
After converting and rewriting, the resulting webpages are stored in a different folder than the download directory. This folder is the one you need to upload to the new website.
Any question, please send an email to support@goodlucksoft.com.